서버와 클라이언트
서버와 클라이언트는 상대적인 개념이다
서비스를 제공하는쪽이 서버이고, 서비스를 제공받는쪽이 클라이언트.
한꺼번에 수백만 명 이상의 사용자로부터 생기는 트래픽을 처리하기 위한 방법은 여러가지.
가장 범용적이고 직관적인 방법 두 가지 : 로드밸런싱, 캐시
로드밸런싱
이란, 서버에 가해지는 부하를 분산하는 것이다.
사용자들의 트래픽을 여러 서버가 나눠 받도록 구성하며 일반적으로 네트워크 장비인 스위치를 할당해 로드밸런싱 할 수 있다. 스위치에서 어떤 서버로 로드밸런싱이 되도록 할지는 소프트웨어적으로 제어 할 수 있다.

스위치라는 장비가 클라이언트의 트래픽을 먼저 받아서 여러 대의 서버로 분산해 주는 방식이 로드밸런싱 이다.
부하분산 효과 외에도 스위치 뒤에 연결된 서버들을 필요에 따라 추가/삭제 할 수 있어 편리하다.
캐시
트래픽 처리를 위한 또 다른 방법.
비용이 큰 작업의 결과를 어딘가에 저장하여, 비용이 적은 작업으로 동일한 효과를 내는 것 이라고 할 수 있다.
데이터의 실시간성을 보장하기엔 한계가 있지만, 성능을 극대화 할 수 있다.
캐시를 이용하면 매번 요청이 들어올 때마다 비용이 큰 작업을 수행할 필요 없이, 미리 저장된 결과로 응답하면 된다.
서버와 브라우저
웹 브라우저란 HTTP라는 프로토콜을 통해 서로 통신하여 웹 서버에 접속할 수 있게 도와준다.
웹 서버와 웹브라우저가 통신하는 원리 :
DNS(Domain Name System)
네트워크상에서 클라이언트가 서버를 찾아가려면 IP주소를 알아야 한다.
하지만 브라우저엔 ip주소가 아닌, 도메인네임 (www.pogeum.com 와 같은) 이 있다.
인터넷에는 이러한 도메인네임을 IP로 변경해주는 DNS가 있다. DNS도 하나의 애플리케이션 서비스이다.
윈도우 명령 프롬프트에 nslookup www.google.com을 을 입력하면, 구글 웹 서버의 ip주소를 알 수 있다.
클라이언트는 DNS를 이용해 구글 웹서버의 ip주소를 얻어, 이 주소로 구글의 웹서버를 찾아가게 된다.
라우터
구글 웹 서버의IP를 가지고 출발한 클라이언트의 요청은 pc에 연결된 랜선, 와이파이 전파를 타고 공유기를 거쳐
인터넷 구간을 지난다. 이 인터넷 회선 중간마다 라우터가 존재한다.
이 라우터는 클라이언트의 요청에 적혀 있는 IP 주소를 기반으로 다음 경로를 안내해 준다.
DNS의 요청을 포함해 클라이언트의 모든 요청은 공유기를 통해 라우터를 거친다. DNS 역시 구글의 웹 서버처럼 공유기를 통해 접근하는 존재이다.
라우터의 안내를 받아 구글 웹서버에 도달한 클라이언트의 요청은
구글의 웹서버에서 실행 중인, 웹 서버 애플리케이션에게 전달된다. 그럼 웹서버 애플리케이션은 클라이언트의 요청에 해당하는 HTML문서를 응답으로 준다. 이 문서는 왔던 길을 다시 되돌아가 최종적으로 클라이언트(웹브라우저)에게 전달된다. 이렇게 서버로부터 응답받은 HTML문서를 사용자가 볼 수 있는 형태로 만드는 과정을 랜더링 이라고 한다.
웹브라우저의 역할
- 사용자가 도메인 네임 입력하면 DNS통해 IP주소로 변환
- 웹 애플리케이션 서버로 요청 보냄
- 응답을 받아 웹페이지 화면에 랜더링 함
IP주소
네트워크상에서의 주소.
. 을 기준으로 구분한 4가지의 숫자조합으로 구성된다.
전 세계 인터넷에 연결된 모든 곳에서 접속할 수 있는 유일한 IP는 공인 IP주소로 부여하고,
각각의 공이 ㄴIP내부에 존재하는 네트워크 망에는 사설IP주소를 부여하는 방식 사용.
집에 설치된 공유기에는 외부에서 접글할 수 있는 공인 IP주소가 할당되고,
포트포워딩 설정을 통해, 공유기에 연결된 스마트폰, 노트북, 데스크톱 등의 기기에는 사설 ip주소가 부여된다.
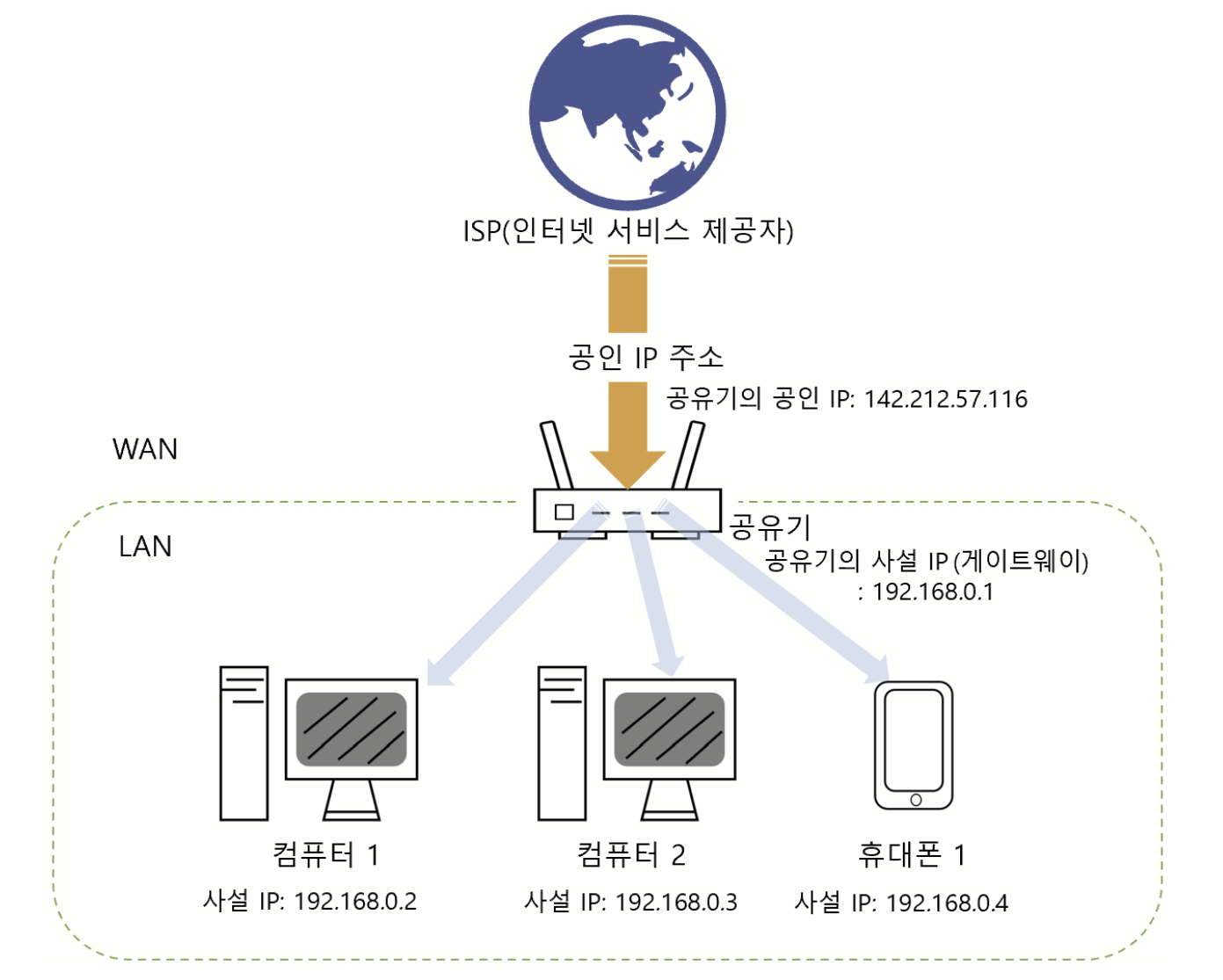
공인 IP주소는 네이버에 검색만 해도 알 수 있다.
사설 ip주소는 명령 프롬프트에 ipconfig 를 입력하면 알 수 있다.
포트
포트 번호는 하나의 IP 주소 내에서 특정 애플리케이션이나 서비스를 식별하는 숫자입니다.
예를들어, 내 로컬 ip주소 (127.00.01?어쩌고) 내에서도 내가 포트번호 여러개로 서비스를 만들 수 있지 않았던가?
port = 8808 , port = 8888 이런식으로 말이다.
여러 개의 서버 애플리케이션에 접근하려면 ip주소만으로 충분하지 않다.
ip주소는 클라이언트의 요청을 물리적인 장치인 서버까지는 안내해 줄 순 있지만, 해당 서버 내에서 돌아가고 있는 서버 애플리케이션까지 전달해 주기는 정보가 부족하다.
각각의 서버 애플리케이션에 정확하게 요청을 전달하기 위해선 포트 라는 추가정보가 필요하다.
참고로, 웹 브라우저는 포트 번호를 명시적으로 적어주지 않아도, 해당 프로토콜의 기본 포트를 요청에 추가해 준다.
포트의 값과 종류
잘알려진포트, 등록된포트, 동적포트.
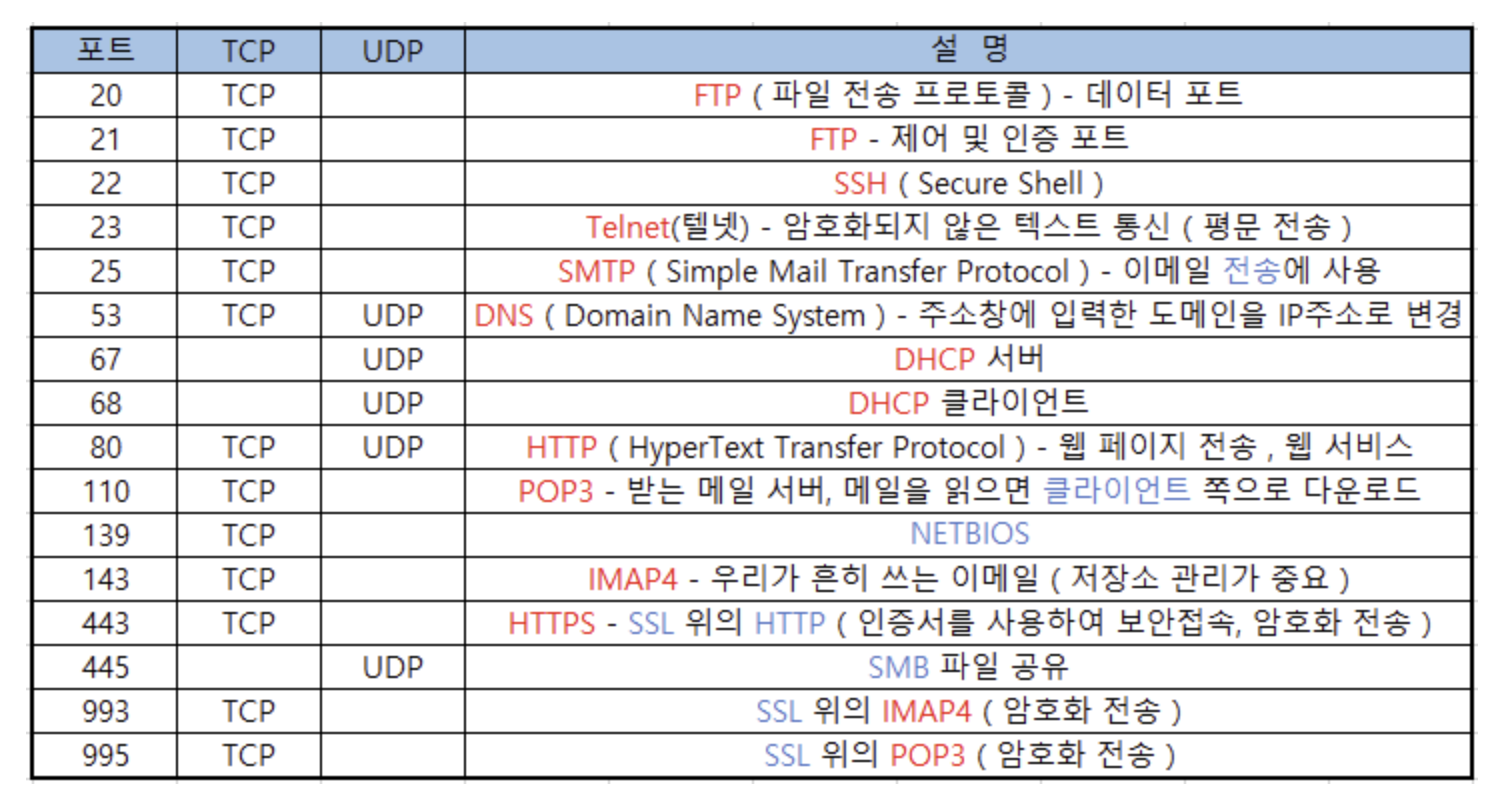
http프로토콜 기본 포트는 80이다.
등록된포트는 특정 소프트웨어에서만 사용하는 프로토콜위해 쓴다.
예로, mysql 은 3306, redis는 6379번.
동적포트는 서버에게 보낸 요청을 되돌려 받기 위해 사용된다. 운영체제에 의해 관리되며 직접 지정할 필요 없다.
서로다른 2개 이상의 애플리케이션은 동일한 포트를 사용할 수 없다.
포트가 중복되면 해당 포트로 들어온 요청을 어떤 애플리케이션이 받아야 할지 모호해 지므로 운영체제가 이미 사용중인 포트에 대한 할당 요청을 거절한다.
웹서버와 WAS
웹서버는 세가지 의미로 사용된다.
1. 웹 서비스가 실행되고 있는 물리적인 형태의 서버 -> 네트워크 장비, 데이터베이스 등 실존하는 물리적인 장치 의미함
2. 물리적인 서버 내에서 실행 중이며 웹 요청을 받을 수 있는 서버 -> Web Server
3. 프로그래밍 언어에 의해 특정 로직이 실행되는 웹 애플리케이션 서버 -> Web Application Server
2웹서버는 보통 정적 콘텐츠 제공에 중점 둔다. 예로, html,css, js, 이미지파일 처럼 사용자가 요청한 컨텐츠를 정적인 형태 그대로 반환해주는 역할을 한다. (Nginx, Apache .. )
3WAS는 이런 정적 콘텐츠에 더해 사용자 요청에 따라 어떤 로직을 실행 시키거나, 그 로직의 결과에 맞춰 서버에 존재하지 않던 콘텐츠를 새로 만들어 응답하기도 한다. (Tomcat, Undertow .. )
보통, 개별 서비스 마다 1,2,3 이 묶음 으로 여러개 구축되어 있다.
예를들어 구글 내부망에 검색서비스, 계정서비스, 로깅서비스 이런식으로.
이렇게 구성된 서비스에선 각자 독립적으로 구동되기 때문에, 같은 상황에서 한꺼번에 세가지가 중단될 일은 없다.
ㅇ
대신 서버와 서버 사이의 통신이 필요하다.
예를들어 사용자가 검색에 대한 로깅작업을 요청하는 경우, 검색 서비스에서 로깅 서비스쪽으로 요청을 할 수 있어야 한다.
이도 http방식으로 한다. 서버와 클라이언트의 개념이 상대적인 서버와 클라이언트의 개념이 적용된다.
이와 같은 형태를 서버와 서버간의 통신이라고 지칭한다.